【數據分析】R|擷取字串|RegEx與常用函數
在抓取資料或清理資料、Mutate整理Dataframe時,我們常常會需要擷取字串,舉凡辨識Email、檔案格式或副檔名(File Extension)、用字分析...等等,抑或最簡單的只想看出vector中含有某個詞彙的比率,各種情境都很常出現擷取或比對字串的需求。
從圖例中,可以清楚看到使用gsub函數,並在Pattern中使用RegEx,依照設定的規則,將逗點空白後與句點之間的字從names這個vector各項揪出來,不論comma前,dot後還有多少字。因此最終篩選出Mr, Mrs, Miss, Master等字。
而除了R以外,在網頁與資料庫互動中,PHP、Javascript也常用到RegEx去擷取、鎖定目標物或標籤,大致上概念一樣,但語法有些微不同。https://regex101.com這個網站上面有針對不同語言所用的擷取demo,可以利用它多做練習,多參閱右下角的Quick Reference。
而除了此篇文章內所介紹較常用的字符,在RegEx還有其他表達式。下一篇我會再講解strsplit,還有別的括號,像是「[]、[^]、{}」,輔以「+」「*」「?」之比較。
擷取字串常用函數
而在這過程之中,勢必需要了解有哪些函數與方法來幫助解決問題。來看看常用的函數包含在哪些Package?- base 內建之基礎套件
- grep:設定要找的詞彙,列舉資料中存在該詞彙的位置(index)。
- grep("pattern", vector)
- grepl:與grep一樣,但l代表logical,列舉之結果為T/F,有該pattern者為TRUE。
- gsub:可以將pattern中( )所鎖定的subpattern再進一步抓出來,結果為( )中內容。
- gsub("(sub)pattern", "\\1", vector)
- gsub("pattern", sentence, "substitution"),把字串中所有含pattern者依substitution做取代。gsub = global substitution
- strsplit:String Split,顧名思義將字串做分割(依據給的pattern)。
- strsplit(sentence, "pattern")
- stringr 需另外載入之套件
- str_detect:偵測到vector之字串中含有pattern者為TRUE
- str_detect(vector, "pattern")
- str_sub:自字串中,擷取設定之始末位置(index)之間的字串。subset of the string
- str_sub(string, start_index, end_index),末位置接受負值,代表倒數第幾個。
grepl vs. str_detect?
基本上,我認為grepl與str_detect沒有差異。個人在處理時較喜歡利用str_detect的方法判斷dataframe欄位是否有想要的pattern,直接搭配if放置其()內使用,做後續的事,名稱也較好記,使用上也較簡易直覺,data擺前面、pattern擺後方。
stringr還有其他好用的function,取名也都很直覺,以str_開頭,搭配意義明確的英文字。像是str_replace_all、str_trim、str_remove、...等,也都能搭配RegEx使用。詳細可以參閱stringr套件的文件:https://cran.r-project.org/web/packages/stringr/vignettes/stringr.html
RegEx:Regular Expression
翻譯作正規表達式,為什麼需要了解它?在使用填pattern時,除了固定字串,可以用這種方式來抓廣泛符合pattern的集合,非常方便。舉例而言,pattern內容可以放^.*, (.*?)\\..*$,那這串符號代表什麼呢?
- 首先要知道的「.*」
- 「.」代表一個任意字元,不管是A-Z, a-z, 0-9, */+-等等。
- 「*」代表「多」個,在ERD時也會用這個符號代表多。(0~n個)
- →「.*」即代表多個任意字元
- ^代表開頭,$代表結尾。
- \\是迴避特殊字所用的字符,參考小訣竅。
- ()是鎖定要抓的subpattern(gsub會透過後面的\\1篩選抓出第1個()之內容)
- ?代表可有可無
→「^.*」由任意多字元開頭
→「, 」碰到comma與space(這邊當作一般字元)
→「(.*?)」為擷取不一定存在的任意多個字元
→「\\.」碰到dot
→「.*$」由任意多字元結尾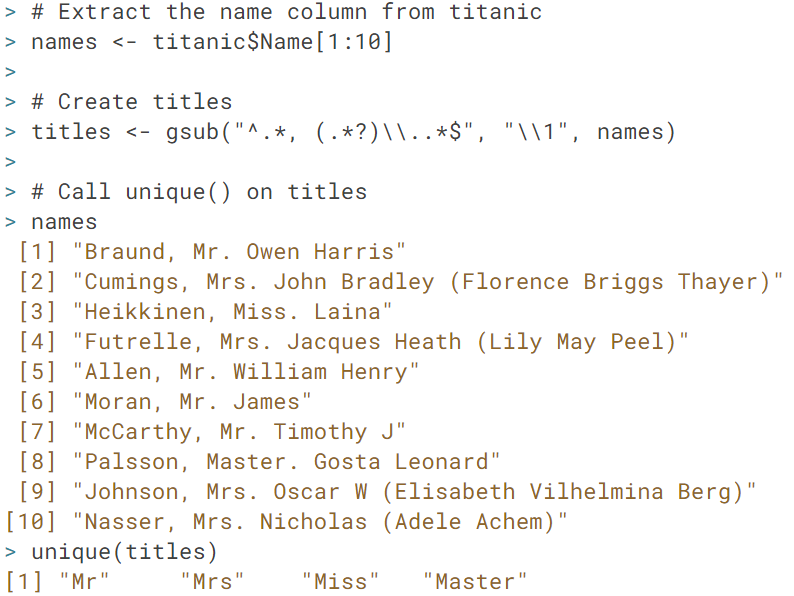 |
| [Datacamp - Intermediate R Practice] |
小訣竅
- \\:正確選定後面的特殊字元,比方我想要擷取「.」,直接輸入「.」的話因為是特殊符號,代表著一個任意字元,會以為我想要找任意字元,所以如果我要鎖定找「.」,就必須在「.」之前加入「\\」,形成「\\.」就能正確抓到英文句點。
- 類推"(\\[.*\\])"可以擷取包含[]及位在其內的字串(string, character)。
- 依我觀察,值得注意的是較常用的特殊字符除了^和\\屬於前綴(修飾後字元)外,其他都是後綴(修飾前字元)。當然,括號為前後包覆,不屬於此部分討論範圍。
結語
當去深入了解RegEx後,套在這些function中活用,就能更便於過濾字串,從茫茫辭海中留下自己想要的資訊,快速協助作業,也可以擴大搜索範圍,不用鎖定單一字串。熟能生巧,需要就是多練習即可,搭配邏輯判斷還有適合的函數。而除了R以外,在網頁與資料庫互動中,PHP、Javascript也常用到RegEx去擷取、鎖定目標物或標籤,大致上概念一樣,但語法有些微不同。https://regex101.com這個網站上面有針對不同語言所用的擷取demo,可以利用它多做練習,多參閱右下角的Quick Reference。
而除了此篇文章內所介紹較常用的字符,在RegEx還有其他表達式。下一篇我會再講解strsplit,還有別的括號,像是「[]、[^]、{}」,輔以「+」「*」「?」之比較。

留言